Contexte
La base de données de DBF Automobiles centralise plus de 500 000 fiches contacts. Avec le temps, de nombreux doublons sʼy sont glissés : même nom avec une légère variation, adresse partagée, téléphone pro en commun... Ces doublons perturbent les usages quotidiens, notamment en CRM et marketing.
Une méthode simple était déjà en place (comparaison directe des emails ou numéros de téléphone), mais elle se montrait insuffisante. Il devenait nécessaire de passer à une approche plus intelligente.
Problématique
Comment identifier de manière fiable des doublons lorsque les informations ne sont pas strictement identiques ?
Et comment le faire à grande échelle, tout en gardant la main sur les décisions finales ?
Les besoins :
- Détection souple mais pertinente
- Modèle entraînable et interprétable
- Capacité à traiter plusieurs centaines de milliers de lignes
- Possibilité d’intégration dans les outils internes
Recherches
Après quelques explorations, il est apparu que le sujet relevait du record linkage, une branche de la data science qui vise à relier différentes entrées correspondant en réalité à la même entité.
J’ai rapidement trouvé la bibliothèque Dedupe, qui cochait toutes les cases : open-source, bien documentée, et basée sur du machine learning supervisé. Exactement ce qu’il me fallait pour démarrer une première version.
Prototypage
Un premier prototype a été mis en place sur un échantillon de 5000 lignes. Objectif : entraîner le modèle à reconnaître les doublons grâce à des paires de contacts étiquetées manuellement.
J’ai développé un script Python avec une API Flask pour encapsuler l’entraînement et faciliter les tests. Une interface d’annotation a aussi été imaginée pour fluidifier la validation manuelle.
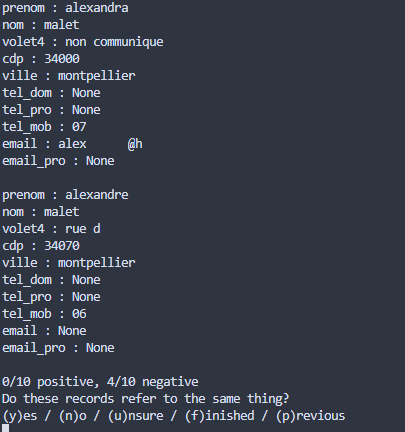
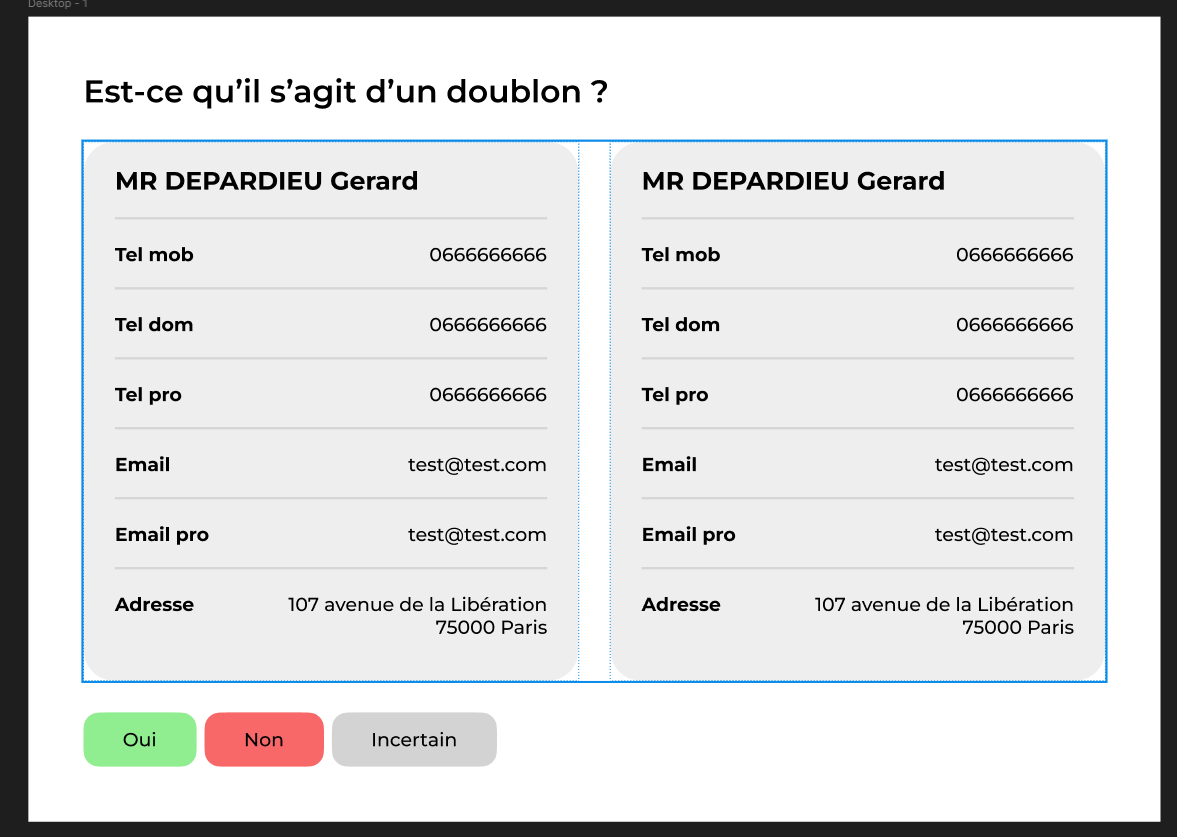
Pour améliorer la qualité des suggestions, plusieurs features ont été choisies comme critères de comparaison :
- Nom de famille
- Numéros de téléphone (mobile, pro, domicile)
- Emails personnels et pro
- Rue
- Ville
- Une feature amplifiée combinant rue + ville
J’ai également ajouté un bouton permettant d’enrichir dynamiquement le modèle pendant qu’il s’entraîne, ce qui a considérablement amélioré sa pertinence au fil des itérations.
Réalisation
Une fois le modèle suffisamment entraîné, j’ai conçu un second script pour le lancer sur la base de production, en me connectant à PostgreSQL. J’ai procédé par lots croissants (5000, 10000, jusqu’à la base complète) pour valider progressivement les performances.
Le seuil de similarité a été réglé à 0.10, car c’est celui qui offrait les meilleurs résultats lors des tests : suffisamment de doublons identifiés, sans générer trop de faux positifs.
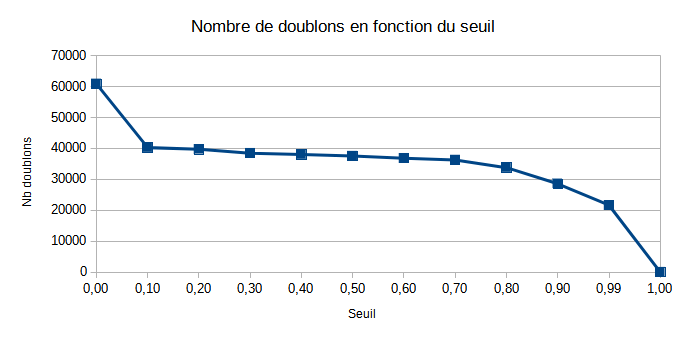
Le seuil de 0.10 a offert un bon équilibre entre pertinence et quantité.
Résultat
Le système en place permet aujourd’hui de :
- Repérer intelligemment les doublons, même avec des infos partielles
- Réentraîner le modèle à tout moment, de manière itérative
- S’intégrer facilement aux outils internes de l’entreprise
Ce projet m’a permis d’explorer concrètement l’application du machine learning à un vrai cas métier, tout en mettant en place une solution durable et facilement maintenable.

Terminé le
dimanche 30 mars 2025